一直以來,通過研究表明,人類研發的機器也能學習到人類看待這個世界的視角,無論其是否有意。對于閱讀文本的人工智能來說,它可能會將“醫生”一詞與男性優先關聯,而非女性,或者圖像識別算法也會更大概率的將黑人錯誤分類為大猩猩。
2015年,Google Photos應用誤把兩名黑人標注為“大猩猩”,當時這一錯誤意味著谷歌的機器學習還處于“路漫漫其修遠兮”的狀態。隨后,谷歌立即對此道歉,并表示將調整算法,以修復該問題。近日,作為該項錯誤的責任方,谷歌正在試圖讓大眾了解AI是如何在不經意間永久學習到創造它們的人所持有的偏見。一方面,這是谷歌對外PR(公共關系)的好方式,其次,AI程序員也可以用一種簡單的方法來概述自己的偏見算法。
在該視頻中,谷歌概述了三種偏見:
互動偏差 :用戶可以通過我們和其交互的方式來偏移算法。例如,谷歌把一些參與者召集其起來,并讓他們每人畫一只鞋,但多半用戶會選擇畫一只男鞋,所以以這些數據為基礎的系統可能并不會知道高跟鞋也是鞋子。
潛在偏差 :該算法會將想法和性別、種族、收入等不正確地進行關聯。例如,當用戶在Google Search搜索“醫生”時,出現的大多為白人男性。
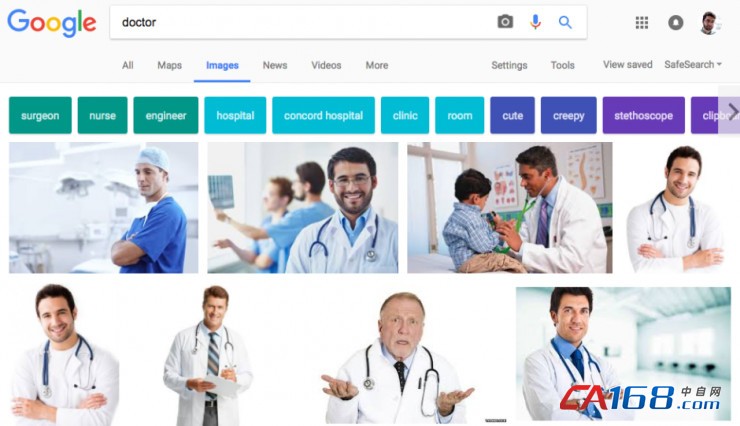
此前 Quarts 發布了一則相關新聞,該報道稱,經普林斯頓大學最新研究成果表明,這些偏見,如將醫生與男性相關聯,而將護士與女性關聯,都來自算法被教授的語言的影響。正如一些數據科學家所說:沒有好的數據,算法也做不出好的決策。
選擇偏差 :據了解,用于訓練算法的數據量已經大大超過全球人口的數量,以便對算法實行更好的操作和理解。所以如果訓練圖像識別的數據僅針對白人而進行,那么得到的數據也只能來自AI的認定。

去年6月, “青年實驗室”(英偉達、微軟等科技巨擘均是該實驗室的合作伙伴和支持者)舉辦了一次Beauty.ai的網絡選美大賽。該比賽通過人工智能分析,征集了60萬條記錄。該算法參考了皺紋、臉部比例、皮膚疙瘩和瑕疵的數量、種族和預測的年齡等等因素。最后結果表明,種族這一因素比預期發揮了更大的作用:在44名獲獎者當中,其中有36人為白人。















共0條 [查看全部] 網友評論