基于模型的系統(tǒng)工程 (MBSE) 的興起,為企業(yè)數(shù)字化轉(zhuǎn)型提供了新的途徑,通過建立精確的概念模型來管理和分析整個系統(tǒng)的復雜性,為組織提供了更高效、更精確、可持續(xù)的方式來管理和優(yōu)化業(yè)務流程。數(shù)字化轉(zhuǎn)型的重要性雖然被廣泛認知,但實際上大多數(shù)組織變革都面臨著嚴峻的挑戰(zhàn),以致于70% 的復雜的大規(guī)模變革項目最終未能達到既定的目標。數(shù)字化轉(zhuǎn)型失敗存在一系列原因,如員工的參與度不足、管理層支持不力、跨職能協(xié)作不足,以及各方責任不明確等。本文就企業(yè)如何通過MBSE實現(xiàn)數(shù)字化轉(zhuǎn)型進行了研究,提出一種可行的并行化模式,在不影響企業(yè)活動正常開展的同時實現(xiàn)文檔數(shù)據(jù)數(shù)字化的積累,并闡述了構建領域模型數(shù)據(jù)庫的價值和意義,以模型為唯一數(shù)據(jù)源代替絕大部分文檔進行知識儲備和信息傳遞。
1 數(shù)字化轉(zhuǎn)型中的并行化模式
數(shù)據(jù)模型化的必要性
傳統(tǒng)系統(tǒng)工程依賴繁瑣的文檔流程,缺乏對信息進行統(tǒng)一配置控制的機制,導致同一信息在不同文檔多次出現(xiàn),對變革的響應“心有余而力不足”。
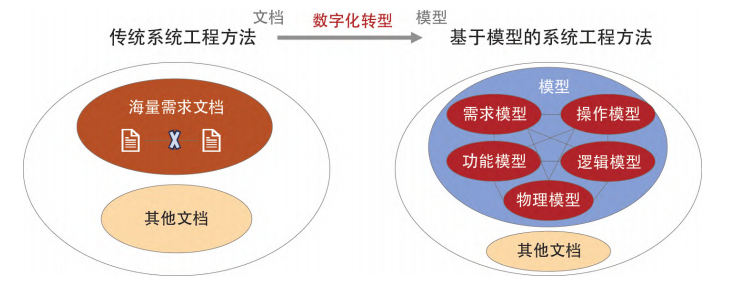
圖 1 傳統(tǒng)系統(tǒng)工程與基于模型的系統(tǒng)工程對比圖
如圖1所示,通常業(yè)務模型是以文字描述或是流程圖形式存在,但在組織工程具體實施的連接相對模糊,導致各文檔間導航困難,無法跟蹤變化。傳統(tǒng)系統(tǒng)工程中需求信息的提取尤其困難,同一信息可能多次出現(xiàn),且在需求基線確定過程中存在信息丟失的問題。傳統(tǒng)系統(tǒng)工程只有對原始需求記錄的非正式鏈接文檔,割裂的文檔信息難以整合到環(huán)境中,需求難以被追蹤到設計和驗證層面。
資源信息在環(huán)節(jié)傳輸和跟蹤中的不對稱,以及數(shù)據(jù)資產(chǎn)管理不善等問題會導致研究人員對需求信息理解出現(xiàn)差異,大幅增加不必要的工作量,從而使產(chǎn)品開發(fā)周期延長、成本增加,難以適應激烈競爭環(huán)境。為解決以文檔為中心的傳統(tǒng)系統(tǒng)工程的難點,采取基于模型的方法進行數(shù)字化轉(zhuǎn)型。通過MBSE提供一種更清晰、一致且易于理解的方式來管理信息,全覆蓋地將業(yè)務與模型相對應,確保數(shù)字化轉(zhuǎn)型的各類信息反映在系統(tǒng)設計中。通過MBSE對領域知識與領域需求升維凝練以形式化建模的方式將其整合,提供導航和跟蹤機制實現(xiàn)信息的配置控制,避免了數(shù)據(jù)的重復,減少了手動操作,提高了工作效率。
1.2 并行化轉(zhuǎn)型模式研究
企業(yè)數(shù)字化轉(zhuǎn)型不是一蹴而就的,牽涉到企業(yè)結(jié)構、流程優(yōu)化、文化轉(zhuǎn)變等多個方面。即使管理層充分認識到數(shù)字化轉(zhuǎn)型的迫切,但推動數(shù)字化戰(zhàn)略的同時,確保過渡期間的企業(yè)業(yè)務正常運轉(zhuǎn)卻十分復雜。在變革的過程中,企業(yè)仍需不間斷地提供服務滿足客戶需求,并在競爭激烈的市場中保持競爭力。并行化轉(zhuǎn)型模式將風險管理納入考量,注重業(yè)務創(chuàng)新和現(xiàn)有業(yè)務的平衡,旨在讓企業(yè)在進行數(shù)字化轉(zhuǎn)型的同時保持業(yè)務的穩(wěn)定狀態(tài)。用進化生物學領域的用語來講,基于模型的數(shù)字化轉(zhuǎn)型更適用于“共生協(xié)同主義”的并行化研制模式,即建立緊密相互依賴的關系,實現(xiàn)更大的合作和協(xié)同效應。
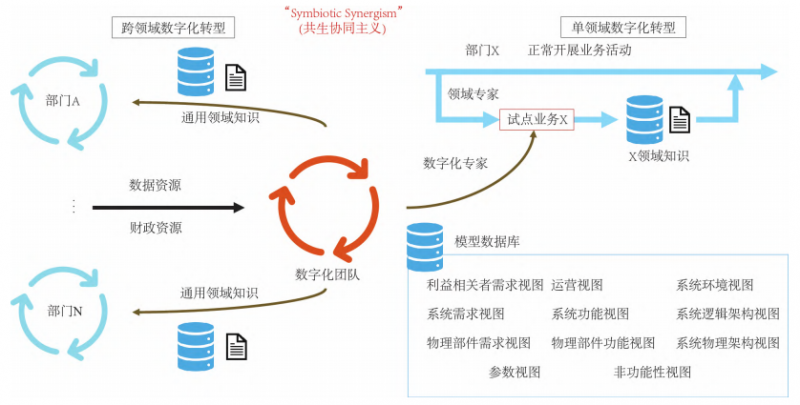
圖 2 數(shù)字化轉(zhuǎn)型中的并行化模式
如圖2所示,基于模型的數(shù)字化轉(zhuǎn)型需要專業(yè)的數(shù)字化團隊作為數(shù)字化轉(zhuǎn)型的中繼站,由數(shù)字化團隊與領域?qū)<覉F隊共同承擔。在跨領域的數(shù)字化轉(zhuǎn)型中,企業(yè)多個部門委托專業(yè)的數(shù)字化團隊進行數(shù)字化轉(zhuǎn)型,各部門提供領域數(shù)據(jù)、領域?qū)<遗c財政支持。領域?qū)<覉F隊整合跨部門的專業(yè)知識,專注于與數(shù)字化團隊協(xié)同工作,尤其是文檔數(shù)據(jù)到模型數(shù)據(jù)的轉(zhuǎn)變工作上,明確領域術語的統(tǒng)一認知,形成通用領域知識,包括模型數(shù)據(jù)庫和使用說明文檔。
這一整體集中的協(xié)同模式有助于資源的集中利用,避免了重復投入,使數(shù)字化團隊更專注于制定和實施數(shù)字化策略。單領域數(shù)字化轉(zhuǎn)型中,部分組織可能難以靠自身推動變革或者對數(shù)字化轉(zhuǎn)型的需求不明確。這種情況下,可以采取在內(nèi)部對個別業(yè)務進行小范圍試點的方式。數(shù)字化團隊派遣專家到企業(yè)部門內(nèi)部協(xié)同工作。這種模式注重提升部門內(nèi)部部分成員數(shù)字化思維和培養(yǎng)數(shù)字化能力。通過試點項目快速取得成效,證明數(shù)字化能實現(xiàn)降本增效效果,并總結(jié)經(jīng)驗教訓且逐步推動數(shù)字化轉(zhuǎn)型。
2 數(shù)字化轉(zhuǎn)型中的模型數(shù)據(jù)庫
2.1 構建領域模型數(shù)據(jù)庫數(shù)字化轉(zhuǎn)型首要目標是構建完備的領域模型數(shù)據(jù)庫以實現(xiàn)文檔信息的數(shù)字化和模型化,涵蓋數(shù)據(jù)的提煉、編輯、共享、存儲、檢索以及最終的歸檔。通過精細的生命周期管理,能夠追蹤和記錄數(shù)據(jù)的變化,確保數(shù)據(jù)的可追溯性和完整性。模型數(shù)據(jù)是通過領域?qū)<遗c數(shù)字化專家共同協(xié)作從文檔中提取凝練的、符合數(shù)據(jù)—信息—知識—智慧的轉(zhuǎn)化DIKW金字塔的理念。這種協(xié)同工作方式來搭建領域模型數(shù)據(jù)庫有助于提高準確度,防止信息孤島的產(chǎn)生,從而促進提取的數(shù)據(jù)綜合且完善,使得相關人員對模型數(shù)據(jù)的使用能達到統(tǒng)一的認知。
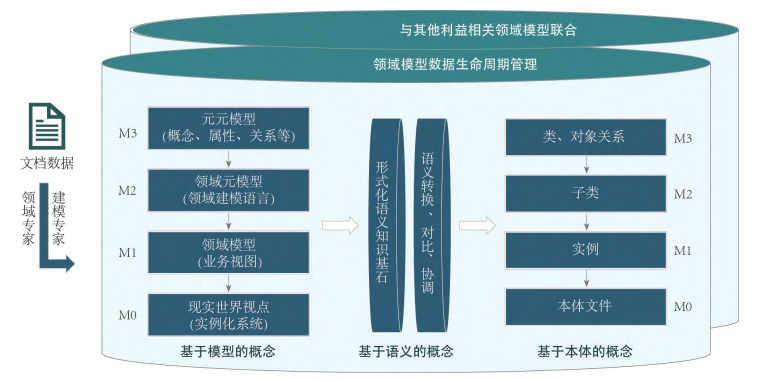
圖 3 領域模型數(shù)據(jù)庫
如圖3所示,通過領域?qū)<遗c建模專家的合作,根據(jù)MOF標準從文檔數(shù)據(jù)中提取凝練出模型數(shù)據(jù),形成領域模型數(shù)據(jù)庫,從底層的數(shù)據(jù)逐漸升華到最高層的智慧,從抽象的通用定義到具體定制實例化。本體的作用在于描述某個領域的知識,通過構建與模型之間的對應關系實現(xiàn)對不同層面的知識的跨領域集成,逐步建立完善的領域模型庫。在各個領域能夠定制化構建領域建模語言,為建模語言使用人員提供指導。
2.2 基于語義的領域模型數(shù)據(jù)
根據(jù)領域的要求可以構建不同的領域元模型,如需求元模型、功能元模型和系統(tǒng)架構元模型等。在通用模型基礎上進行擴展,結(jié)合領域特點進行設計,不改變概念定義的同時定制實例的可行性,確保了在不同階段和不同活動之間協(xié)同工作的一致性。數(shù)字化轉(zhuǎn)型的成功實施不僅需要關注模型數(shù)據(jù)格式,還需要注重對模型數(shù)據(jù)語義的建立和維護,引入語義數(shù)據(jù)轉(zhuǎn)換、對比和協(xié)調(diào)管理,來保障數(shù)據(jù)的一致性、完整性和質(zhì)量。通過語義級別的管理更準確地表達和解釋模型數(shù)據(jù)的含義,確保不同模型之間能夠正確理解和映射所有不同模型數(shù)據(jù)。同時,還應建立形式化的語義知識基石,為整個系統(tǒng)提供了可靠的知識支持。
為了實現(xiàn)這種互操作性,需要在交換格式之外定義交換的語義。只有通過建立共同語義,不同模型之間的信息交換才能正確進行,避免數(shù)據(jù)結(jié)構和語言語法的差異導致的信息偏差。語義層作為中間層次,通過設計模型與本體模型的語義轉(zhuǎn)化算法,制定轉(zhuǎn)化規(guī)則能使設計模型自動生成本體文件,實現(xiàn)對領域知識的本體構建和MBSE模型的語義轉(zhuǎn)化。這種基于語義的一體化本體生成不僅在數(shù)據(jù)一致性方面有良好的優(yōu)勢,還為不同領域協(xié)同和知識集成提供了可能。
結(jié)語
本文提出基于模型的數(shù)字化轉(zhuǎn)型模式,分別從并行化轉(zhuǎn)型模式和領域模型數(shù)據(jù)庫進行研究,強調(diào)數(shù)字化轉(zhuǎn)型團隊與領域?qū)<覉F隊協(xié)同合作的重要性,并構建領域模型數(shù)據(jù)庫,實現(xiàn)對復雜數(shù)據(jù)信息的精細化管理。
未來,還需要對其他方面進一步研究:
(1)數(shù)字化轉(zhuǎn)型中的風險管理與應對策略。通過深入研究風險識別、評估和管理,幫助組織更好地規(guī)避風險,制定應對策略,確保數(shù)字化轉(zhuǎn)型的可持續(xù)性和成功性。
(2)模型凝練的顆粒度研究。從文本到模型提取的過程中,不同領域?qū)δP蛿?shù)據(jù)的要求的精細程度不同,所需要的元素、關系和層次結(jié)構不同,應因地制宜建立更具表達力和適應性的模型數(shù)據(jù)。
(3)模型—語義—本體的轉(zhuǎn)換生成的標準化研究,制定通用的規(guī)范和方法實現(xiàn)各部分映射的規(guī)則,促進知識共享和信息交流。















共0條 [查看全部] 網(wǎng)友評論