�����S��chatGPT�ı����AGI�ķ��s��Ӣ���_������ǰ��δҊ���ٶȰl(f��)չ���@���������GPU�ķ��s��ͬ�r߀�����P�I��ɫHBM��ȸ߾Ӳ��¡�
�����^�����SKHynix����ǰ��ʾ�������HBM�a(ch��n)���Լ������Ժ�������������ڽ���Ҳ������HBM��Ʒ���������@����l(f��)չ���Ј�ռ��һϯ֮�ء����У�ǰ�ߎ����ˌ�����Ӣ���_GH200��֮����߀��ʾ����2024��3����36GB12-HiHBM3E�a(ch��n)Ʒ�����߄t��ʾ����˾�l(f��)����HBM3E12H�����ܺ����������50%������
�����ɴ˿�Ҋ��HBM�ĸ����������ң�HBMҲ�ɞ��˛Q��AIоƬ���\���P�I���@Ҳ���Ǟ��TimothyPrickettMorgan�J�����l�ƿ���HBM����������AIӖ����
��������TimothyPrickettMorgan�ķ������ģ�
����2024���Ƅ�Nvidia��(sh��)��(j��)����GPU�������l(f��)չ������Ҫ������ʲô��
�����Ǽ����Ƴ���“Blackwell”B100�ܘ�(g��u)��҂��_��ԓ�ܘ�(g��u)���Ȯ�ǰ��“Hopper”H100�����փ�(n��i)��ܵ�H200�ṩ�����w�S������
������ԓ��˾�������Ĵ�����������_�e������ûؔ�(sh��)���f�wH100��B100GPUоƬ�������������
������NvidiaAIEnterpriseܛ���ї�����CUDA����ģ�ͺ͔�(sh��)�ق�����������������һЩܛ�����������ȫ������AIӖ�������������ϵĘ˜������^���֛]�С�
�����mȻ�����@Щ�o�ɶ��Ǿ�ă�(y��u)�ݣ��������S�ข�����ֶ����о����ă�(y��u)�ݣ���Nvidia��2024���Ƅ���I(y��)�յ�����Ҫ�����c���X���P�����w���f��Ӣ���_��1�·ݽY(ji��)����2024ؔ�����F(xi��n)����y��Ͷ�Y�Ե���260�|��Ԫ�������ؔ�갴�A���M�������댢ͻ��1000�|��Ԫ�����мsռ50%��������ԃ���������ʽ�w�F(xi��n)��������ô��ʹ��֧���˶�����������аl(f��)�I(y��)���Լ���˾�������\�I�M��֮����������������Ӽs500�|��Ԫ��
�����������750�|��Ԫ�������Y�����ܶ�����������֮һ���Dz���̫���Ğ锵(sh��)��(j��)���ļ�GPUُ�IHBM�ї�DRAM��(n��i)������ľ��~�Y�����@�N��(n��i)���������ஔ�õ��ٶ�׃�ø��졢���ܼ�����ÿоƬǧ��λ���ԣ����֣�FAT�������ֹ�(ji��)������ǧ���ֹ�(ji��)�������ԣ���������M�ٶȲ��]���_���˹����ܼ�����������ٶ���
�����S������Ƽ�(MicronTechnology)����SK����ʿ(SKHynix)������(Samsung)�Ĺ��������У�HBM�Ĺ��������������������M�o�����ٶ�Ҳ�S֮���ơ��҂����ґ��ɹ������o���M��������HBM��(n��i)��ăr���S��HBM��һ���̶����Ƅӵ�GPU�������r����^�m(x��)������
����AMD����57.8�|��Ԫ�ĬF(xi��n)���Ͷ�Y���]����ô���e���Y�����M��Ӣ�ؠ����y�д���Ը���250�|��Ԫ��������횽��������S���@�_���dz����F����������ÿ������150�|��200�|��Ԫ������ˣ���Ҳ�_��������HBM��(n��i)���ϓ]����
������NvidiaGPU�������I(y��)����������һ�������ǣ���GenAI���s�r�����͑�Ը��锵(sh��)������(sh��)ǧ������(sh��)�f����(sh��)��(j��)����GPU֧�����κ��M�á��҂��J����2022��3��������ԭʼ“Hopper”H100GPU�ăr�����e����SXM�����������ھ���80GBHBM3��(n��i)�桢�ٶȞ�3.35TB/��Ć�H100����r���^30,000��Ԫ���҂���֪������96GB��(n��i)�����ٶȞ�3.9TB/���H100���M�������҂����ƜyNvidia������141GBHBM3E��(n��i)�����\���ٶȞ�4.8TB/���H200�O������M��H200�����cH100��ȫ��ͬ��“Hopper”GPU������(n��i)�����������76.3%����(n��i)�控�������43.3%��H100оƬ�����������1.6����1.9�������]���~���������ζ����Ҫ���ٵ�GPU�����ĸ��ٵ������ᘌ��o�B(t��i)��(sh��)��(j��)��Ӗ���o��ģ�ͣ��҂��J���cԭʼH100�����Nvidia�����p�ɵ؞�H200��ȡ1.6����1.9�����M����
�����S�t�������S������ƶ�Ҏ(gu��)�t
�����҂��������fH200�ڵڶ������_ʼ�l(f��)؛�r�͕��l(f��)���@�N��r�����҂��J��Ӣ���_����ؔ�Ք�(sh��)��(j��)��߀ՄՓ�՚v���ȡ����҂�ֻ���f�@�ӵ��e������߉�����ܴ�̶���ȡ�Q��AMD��“Antares”InstinctMI300XGPU�����������M��ԓ����������192GB��HBM3���\���ٶȞ�5.2TB/����MI300X���и����ԭʼ���c������(sh��)������HBM������Nvidia��H200��36.2%��������H200��10.4%��
�����������ElonMusk�����һ�K�X��ـ��AMD�]���������κ��������ˌ�MI300X��ȡ�M���ܶ���M���������н��h�Qԓ��˾����Ŭ�����������֡������HBM3E��(n��i)���I�����Ա���Nvidia�ĸ�����MI300ʹ�þ��а˸�DRAM�ї���HBM3��MI300�еă�(n��i)�������������̖�͎���������������Q��r��ٶȸ����ʮ���߶ї�HBM3E���@��ζ������������50%������Ҳ����������25%��Ҳ�����f��ÿ��MI300X����288GB��HBM3E������6.5TB/��Ď�����
������(j��)�Ɯy���@��һ����(j��ng)�^�����OӋ��MI350XоƬ���҂����ܕ��@�ӷQ�����������ֵʧ���Δ�(sh��)�Ј�(zh��)�����ஔ��Č��H���������������࣬����Nvidia��H100���S��H200�r���l(f��)�����ǘ���
�����������@�ӵı��������҂���ՄՄHBM�I��l(f��)�����������҂�����SKHynix�_ʼ��ԓ��˾չʾ��16��оƬ�ߵ�HBM3E�ї���ÿ���ї��ṩ48GB��������1.25TB/��Ď�����MI300X���8����(n��i)����������Ɍ��F(xi��n)384GB��(n��i)���9.6TB/�뎧����
���������@Щ��(sh��)�������Ͳ��،�CPU����Uչ��(n��i)���������̎����������ؓ�d��������
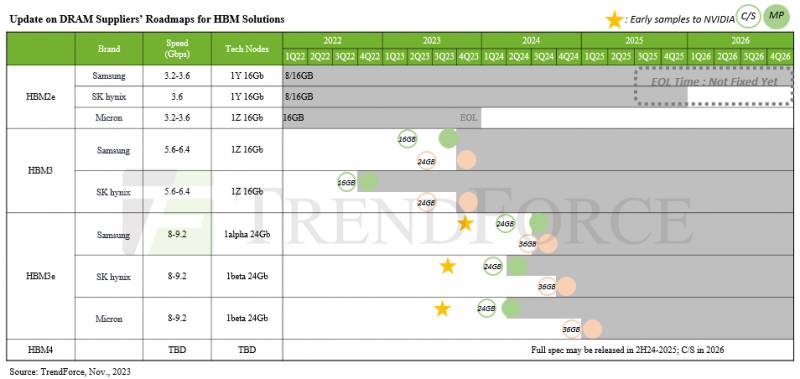
�����҂�߀�]�п����P��SK����ʿʮ����HBM3E��(n��i)��Ľ�B��Ҳ��֪����ʲô�r��������ȥ��8����SK����ʿչʾ�˵����HBM��(n��i)��͵�һ��HBM3E��(n��i)������(j��)�Qÿ���ї����ṩ1.15TB/��Ď���������������Trendforce��(chu��ng)����HBM·���D��ʾ���҂����A�����ṩ24GB��36GB�������@��ζ��8�߶ї���12�߶ї���
����
����ȥ��8����Nvidia�@Ȼ���ɞ��@ЩоƬ�Ĵ�͑��������Ђ��ԷQSKHynix���@��24GBHBM3E��(n��i)�挢���ڼ����Ƴ���“Blackwell”B100GPU��������������@�ӣ���ôBlackwellGPUСоƬ�ϵ�������(n��i)����������a(ch��n)��144GB�����������B100���b���A�ھ��Ѓɂ�GPUСоƬ���t��ζ�����������288GB��������13.8TB/�������y�f��������Σ�����ֻ��5/6���á�Ҳ�п���-���҂�ϣ������-B100����������һ��GPU������ϵ�y(t��ng)ܛ���ăɂ�GPU������ɂ�оƬ�MAMD“Arcturus”MI250X�������ǘ���������MI300X�ǘ���������8���^С��GPUоƬ�M�@��������������������������������һ��GPU��ϵ�y(t��ng)ܛ�������҂�������������l(f��)��ʲô��
��������Ƽ�(MicronTechnology)�M��HBM�I���^�������b�ڹ�����ȱ��������ʢ��ԓ��˾�o����ԓ�I�����ܚgӭ��ԓ��˾�����ʾ���������_ʼ���a(ch��n)����HBM3E��(n��i)�����@��һ�N�˸߶ї�������24GB�����a���fԓ��(n��i)����H200GPU��һ���֡��҂�?n��i)��?�½�B�^��MicronHBM3E׃�w�����_�\���ٶȞ�9.2Gb/����ÿ���ї��ṩ1.2TB/��ă�(n��i)��������߀�Q����HBM3E��(n��i)�����������“�����a(ch��n)Ʒ”��30%�����������ՄՓ�����HBM3E���^��
��������߀��ʾ�������_ʼ����12��36GBHBM3E׃�w�M���͘������\���ٶȌ����^1.2TB/�롣����]��¶��1.2TB/�����١�

����������Щ�r���������Ƴ���ʮ���߶ї�HBM3E���@Ҳ���������a(ch��n)Ʒ��ԓ��˾��̖��“Shinebolt”��
����Shineboltȡ����ȥ���Ƴ���“Icebolt”HBM3��(n��i)�档Icebolt�ї�ʽDRAM��(n��i)���������24GB��ʮ���Ӷї��ṩ819GB/��Ď�����ShineboltHBM3E��36GB�ї����ṩ1.25TB/��Ď���������SKHynixHBM3Eʮ���߶ї�һ����
���������ڹ������a�����“����AI���Õr���AӋ�c����HBM38H�����AIӖ����ƽ���ٶȿ����34%��ͬ�r�������յIJ��l(f��)�Ñ���(sh��)������34%��”�U��11.5��������”����ָ�����@�ǻ��ڃ�(n��i)��ģ�M�������nj��H���˹����ܻ�����

�������ǵ�ShineboltHBM3E12H�F(xi��n)���ṩ��Ʒ���AӋ��6�µ�ǰȫ��Ͷ�a(ch��n)��
�����@Щ12�ߺ�16�ߵ�HBM3E�ї������҂���2026��HBM4�l(f��)��֮ǰ�����е����˂�����ϣ��HBM4����2025����F(xi��n)�����o�Ɇ����҂����R���Ƅ�·���D�����ĉ��������@�ƺ���̫��������(j��)�y��HBM4�ă�(n��i)��ӿڌ�����һ�����_��2,048λ��HBM1��HBM3Eʹ����1,024λ��(n��i)��ӿ�����̖��ݔ�ٶȏ�AMD�cSKHynix�OӋ����2013�꽻���ij�ʼHBM��(n��i)��������ѽ�(j��ng)��1Gb/�����ӵ�9.2Gb/�롣�ӿڼӱ������S�ɱ����ٶ�����Ҫ������(n��i)������ӿ�������һ��ĕr��ٶ��ṩ�o�����Ď����������S���r��ٶ��ٴ���������������u������������������һ�_ʼ����ÿ���_9.2Gb/����ٶ��Ƴ����҂�ֻ��֧�����ߞ��λ�ăr����
��������·���D��ʾ��HBM4���ṩ36GB��64GB���������(q��)���ٶȞ�1.5TB/�뵽2TB/������˿�������nj��ٺ����١����ٺ���Ļ�������ڰl(f��)���r������ȫ�M��������Մ�������������������ȼӱ�������ʹ�����͎����ӱ����AӋHBM4������ʮ����DRAM�ѯB���H�˶��ѡ�
������2026����һ������ĉ��������У�HBM4������2,048λ�ӿ�����������_�ϵ�11.6Gb/����̖��ݔ������24����DRAM�ѯB������33.3%�ܶȵ�DRAM��(n��i)�棨4GB������3GB������ˣ�ÿ���ї����ٶȼs��3.15TB/�룬ÿ���ї����ٶȼs��96GB��Ŷ�����҂��ͯ���������Oһ��GPU�ͺ��w��ʮ�ׂ�СоƬ��ÿ��СоƬ�����Լ���HBM4��(n��i)����������@����ÿ��GPU�O���ṩ37.8TB/��ľۺσ�(n��i)�控�����Լ�ÿ���O��1,152GB��������
�������@���Ƕȁ���������(j��)Nvidia���f����һ��1750�|������(sh��)��GPT-3ģ����Ҫ175GB���������M������������҂�����ӑՓ����ՓGPU�ϵă�(n��i)���С����܉�̎��1.15�f�|������(sh��)����������GPT-3Ӗ������Ҫ2.5TB��(n��i)������d��(sh��)��(j��)�Z�ώ졣�������Hoppers����80GBHBM3��(n��i)�����t��Ҫ32��Hopper��������@헹��������҂���32�_�O�������������14.4��������܉���d��������Ĕ�(sh��)��(j��)�����҂����O���O���ϵĎ���Ҳ�߳�11.3����
����Ոע�⣬�҂��]���ἰ�@ʮ�ׂ�GPUСоƬ��ʧ����r���ڴ����(sh��)��r�£��Գ��^80%���������\���κΖ|�����dz����֣��e�Ǯ��������Բ�ͬ�ľ��Ȉ�(zh��)�в�ͬ�IJ����r���҂���Ҫ�����|�l(f��)���c����/��ı��ʻ֏��������҂���Ҫ����һ�_12�װl(f��)�әC���������ć������팍�Hι�B(y��ng)Ұ�F��
�����҂��IJy����80GB��H100��HBM3��(n��i)��s������ֵ������֮һ������Ҳ�s������ֵ������֮һ���@��һ�N���GPUоƬ�N�ۺ�����ķ���������Nvidia�ѽ�(j��ng)������C�����ǘӣ����@�����ǘ�(g��u)��ƽ���Ӌ������ķ���-����Ӣ�ؠ�����X86оƬ�Ϸ���һ���DRAM��(n��i)�������������ȫ���u�o�҂�һ��——�ɂ��������g�}�����IJ���һֱ�ǔ�(sh��)��(j��)����ͨ��Ӌ������_�����҂�߀��Ҫ����ă�(n��i)�������͎�����
������������ʹ���@��������BeastGPU����������������11.3������ô�cԭʼH100�����Ӌ��������ֻ������4�����ڏ��������ϣ�H100��FP64�����µ��~���ٶȞ�67teraflops����FP8���ȣ�δʹ��ϡ���ԣ��µ��~���ٶȞ�1.98petaflops��������@��TP100GPU�ͺ��w��FP64�µ��~���ٶȞ�268teraflops����FP8�µ��~���ٶȞ�7.92petaflops��ÿ��GPUСоƬ�����܌���H100оƬ���ܵ�����֮һ�����ҿ��������С���ķ�֮һ�����֮һ�����wȡ�Q��ʹ�õĹ�ˇ���g�����O����TSMC2N��Intel14A�c������H100��ʹ�õ�TSMC4N���������@���҂�ՄՓ��2026����
�����@�����҂���Ҫ�����ǷNҰ�F������҂��y������260�|��Ԫ������δ��߀��500�|��Ԫ���ϵ�ǰ�����@�����҂������������Ǵ�����HBM��(n��i)���Ӌ�����涼���M������
�������y�f�@�����M�����X���㲻���ܴ��Ԓ�oFry'sElectronicsԃ��2026��HBM4��(n��i)����Ј��r���Ƕ�����һ������F(xi��n)ry's�ѽ�(j��ng)���ˡ���һ�������҂��F(xi��n)�������o���ܺõ��˽�GPU������������������̞�HBM2e��HBM3��HBM3e��(n��i)��֧�����M����ÿ���˶�֪���������J������֪������HBM��(n��i)������ڌ���(n��i)��朽ӵ��O����κ��н���ǬF(xi��n)���˹�����Ӗ������������ăɂ���Ҫ�ɱ�������Ȼ�����ʹ��Ƭ��SRAM����ͨDRAM���˳��⡣��
����

�������Ј��������ڷ�������������������256GBDDR5��(n��i)��ģ�K��4.8GHz���\�еăr��s��18,000��Ԫ��ÿGB�s��70��Ԫ�����H�ɔUչ��32GB�ĸ���ģ�KÿGB�ɱ��H��35��Ԫ����ˣ�HBM2e�ăr��s��ÿGB110��Ԫ��“���^3��”���������Nvidia�D����ʾ��96GB�ăr��s��10,600��Ԫ�����y�fHBM3��HBM3E��������ԓ�O���“�Ј��r��”�Ͽ���ֵ�����X��������_��HBM3�H����25%����ôH100���Ј��r��s��30,000��Ԫ80GB������HBM3�ăr���8,800��Ԫ���D(zhu��n)��96GBHBM3E���ܕ�����(n��i)��ɱ���ߵ�“�Ј��r��”��16,500��Ԫ����鼼�g�ɱ���������25%�������~���16GB��(n��i)���H10096GB���Ј��r�s��37,700��Ԫ��
���� �����P����141GB����������ij�Nԭ����144GB����H200�ăr��Ă��Ԍ�������Ȥ��������@�N��(n��i)��r��ӳ���——�҂����R���@Щ���ǯ���Ĺ�Ӌ——��ô141GB��HBM3E����rֵ�s��25,000��Ԫ���������@�ӵăr����H200��“�Ј��r��”�s��41,000��Ԫ����ע�⣺�@�����҂��J��Nvidia��HBM3��HBM3E��(n��i)��֧�����M��——�@����������γɱ�——���Ƿ���o��K�Ñ��ăr��
�����҂��J��q���������^25%����������(n��i)��������HBM3��Ȼ����������HBM3E���Ƹ߃�(n��i)��r����ʹ������Ј��ς���NvidiaGPU�r��
����Ոӛס���@ֻ��һ��˼�댍ּ��չʾHBM��(n��i)�涨�r��ο���Nvidia��AMD����Ͷ��ԓ�I���GPU��(sh��)�����������෴����(n��i)��β�����ړu��GPU�Ĺ�����(n��i)�������͎����cH200�����Խ��Խ�o�������Nvidia�H���~��ă�(n��i)�漰���~����ٶ���ȡ�����Ե��M�ã���ô���H�O��Č��HЧ�ʕ�����������ԃr��Ҳ������������Nvidiaֻ�nj��@Щ�������H100��H200�M�ж��r���Ա���������̓�(n��i)�������_��ƽ������ô�����X�͕��ٵö࣬��Ҫ�����X�͕���ö���
�����ό��f���҂���֪��Nvidia����ʲô��Ҳ��֪��AMD��MI300�@��HBM3E���������ʲô���F(xi��n)�������M��ԓ�I���HBM������������50%������SKHynix�����nj��a(ch��n)�������2�����@��һ���ܴ�Ĕ�(sh��)������������GPU��GPU���������Ј��ϵ�HBM��(n��i)����Ȼֻ������3���������ă�(n��i)������������f����3�����@����һ�����Խ��r�ĭh(hu��n)�������@�N�h(hu��n)�������˂�����߸����M��Ӌ�����漰���(n��i)��ăr�������^�m(x��)�M���ܱ��ؔUչHBM��(n��i)����
�����@���Ǟ�ʲôֻҪNvidiaƽ�_�^�m(x��)�ɞ����x���܉�֧���߃rُ�IHBM��(n��i)����ˣ���Nvidia(li��n)�τ�(chu��ng)ʼ�˼���ϯ��(zh��)�й��S�ʄף��Ϳ����O���˹�����Ӗ���IJ����̓r����
�����Q����֮������GPU��HBM���f�������挦�Ķ�����������















��0�l [�鿴ȫ��] �W(w��ng)���uՓ